Picking up where I left off last time here are some more shots of the spherized terrain with a properly calculated per-vertex tangent basis.



Obviously the terrain cubic heightmap I used was good 'ole Earth (and the heights are a bit exaggerated, ha). It looks pretty bland but what's important (at least right now) is what's going on under the hood.
The heightmap I used is a high-resolution (downsampled to 4096x4096) 16-bit tiff DEM based off of satellite scanned terrain data. Because DEM's are rectangular grid based by nature, I needed to find a way to transform a two dimensional topographical map into a cube map. To do this I created a nifty little program that takes a 2D rectangular image with a 2 to 1 proportion, maps it to a sphere using either a spherical or cylindrical projection, then renders the sphere from the inside out to a cube map. The result is taking something like this:
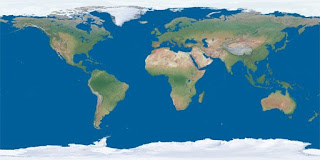
and converting it into this:
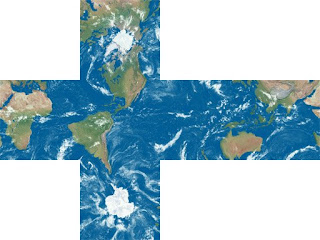
Notice how the cube is reversed? That's a byproduct of rendering from INSIDE the sphere and while it is correct, it can be easily corrected (if needed, i.e. if the object used a different uv mapping). The same process can be done to a heightmap, assuming we make sure to support 16/32-bit floating point colors to preserve that nice precision which can then be used to create the spherical terrain.
This is also super handy in cases where I want to use a cube map as opposed to a rectangular (sphere mapped) texture. Why would I want to do this you may ask? Well it turns out spherical textures exhibit some aliasing near the poles due to how the pixels are distributed to those areas. By using a cube map it is possible to use a lower resolution cube map to represent a much higher resolution 2D map with the same level of detail. The catch is that in benchmarks I've done the cube map performs slightly slower. I was a little surprised because although a rendering cube map can certainly be slightly costly if your ray samples are mostly random, texturing a sphere should be pretty cache friendly as the rays are all adjacent and basically wrap around the surface of the sphere (the texture coordinates are just a vector from origin to vertex, interpolated per-pixel). Perhaps there is an intrinsic cost to sample from face to face. Or maybe it's some kind of driver issue (when in doubt, blame the drivers :-). The other gotcha is that it's more difficult to stream in cube maps for very large worlds (if you were going in that direction).
It's also possible to do the reverse, albeit with some 2D processing as opposed to 3D. In other words, to convert a cube map to a 2D texture. I chose to implement this feature for the cases in which I wanted to procedurally generate a planetary texture that can be easily touched up and texture mapped in the traditional way. The transform is pretty simple and involves first calculating a polar coordinate for each pixel then transforming that into a cartesian vector that can sample the cube map. The sampled color then becomes the new color for that pixel. As an example, here is a random cube map I found on the internet:

And here is how it looks converted to a sphere mapped texture.

What a nice panorama! The nice thing with doing it this way is that supersampling (for nicely anti-aliased images) is easier to do by rendering at a higher resolution then downsampling to the desired size. It's not as simple with the cube render as you need some massive resolutions (which are still not so well supported on cube maps), plus, it's easy to run out of video card memory, ex: if you wanted to do a final render of a 32-bit 1024^2x6 texture at 4x supersampling you'd need 4096x4096x6x4 bytes per pixel = 384MB. For a 128-bit float heightmap it's 4 bytes per-CHANNEL, so 4096x4096x6x16 bytes = 1536MB!! This doesn't include the memory needed for your source assets or geometry buffers. :-)
A solution to this is to break up the texture into multiple blocks which are then saved out individually and later stitched together and resampled as a post-process. In the case of the cube map render you would just render each face to a texture. All of this is pretty unnecessary of course unless you're really trying to squeeze out some quality that may or may not come from such high resolutions.
Another nice thing that came out of this line of research was an elegant way to render a skybox using a cubemap on a single quad, that is to say two triangles that forms a square over the screen as opposed to say the 12 triangles required to actually draw a box. It's a nice little trick that takes advantage of the way in which the view transform relates to the 2D clip space screen plane. Even though it's 2D there is perspective as you rotate the view around. In addition I found a nice way to set the FOV. While nothing revolutionary, it's simple and elegant and probably prevents a stall or 2 in the pipeline somewhere. It also means I don't have to code up yet another box any time I want a skybox so I'm pretty happy about that.
Alright one more teaser to bow me out.
















